No seas fanboy de ningún modelo
TL;DR
- Mi gráfica de uso 2025: Claude → GPT → Gemini → Claude. Cero lealtad.
- Cambié de Claude en marzo porque ocultaba errores con parches en vez de arreglarlos
- Los benchmarks no reflejan tu stack; el modelo que lidera puede ser horrible para ti
- Guía práctica: ten 2-3 modelos listos, prueba cuando algo falle, no migres todo
Mi año en Cursor
Esta es mi gráfica de uso de modelos en Cursor durante 2025:
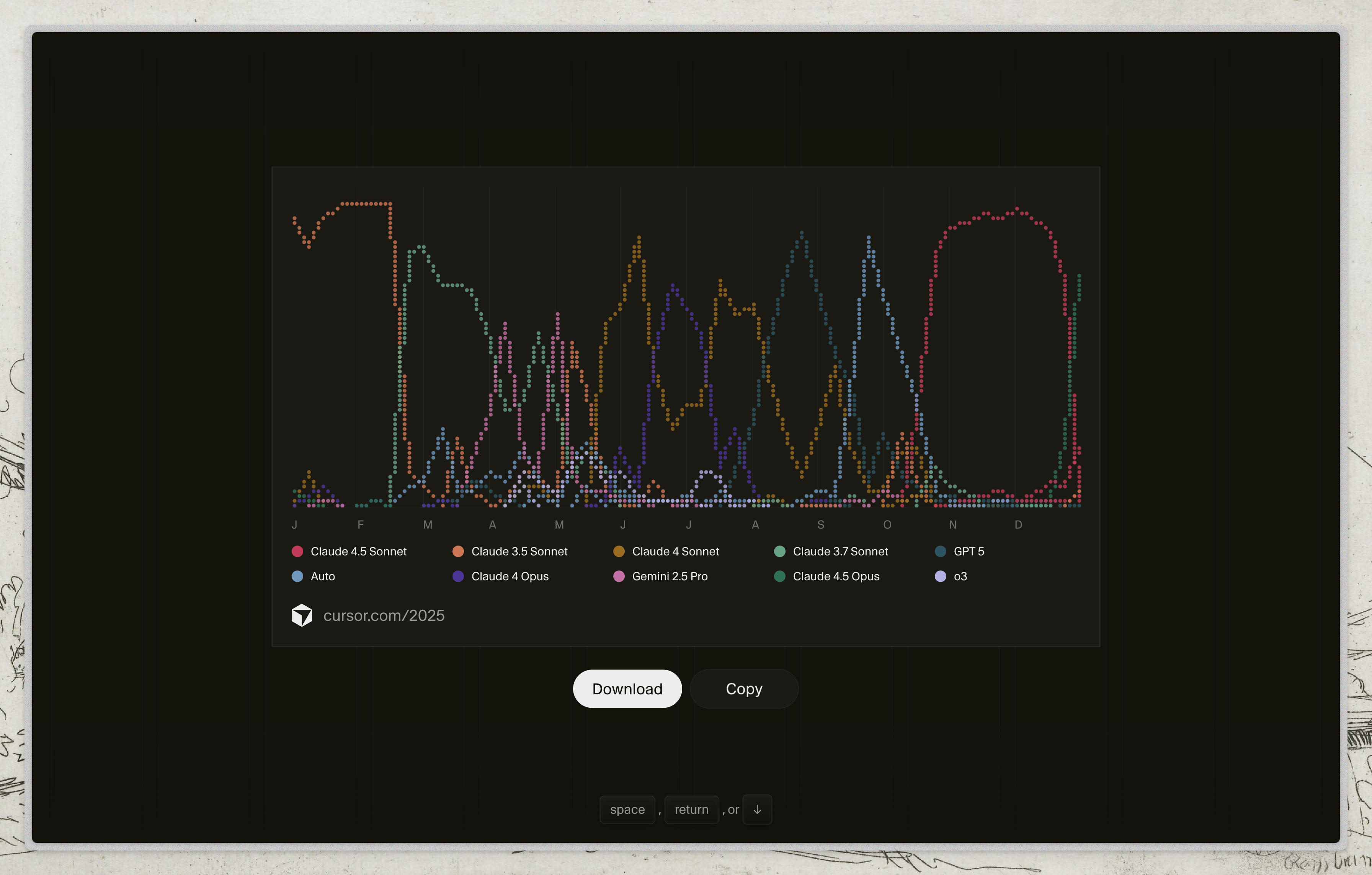
No es una encuesta. No son datos agregados de “la comunidad”. Es mi historial personal de un año escribiendo código con IA.
Y lo que muestra es que he saltado de modelo en modelo sin ninguna lealtad.
Lo que pasó realmente
Enero-Febrero: Claude 3.5 Sonnet
Empecé el año con Claude. Funcionaba bien, era mi default.
Marzo-Mayo: GPT 5
Cambié. ¿Por qué? Claude había empezado a hacer algo que me sacaba de quicio: inventaba parches que ocultaban errores en vez de arreglarlos.
Ya escribí sobre esto en detalle en Sonnet y el problema del hardcode. El resumen: prints de debug que se quedaban para siempre, try/except que silenciaban todo, valores hardcodeados que “funcionaban” en el test pero explotaban en producción.
El código “funcionaba” porque el error estaba oculto. GPT 5 era más honesto: te decía “no sé” o fallaba de forma visible. Prefiero un error ruidoso que un parche silencioso.
Junio-Agosto: Gemini 2.5 Pro y Auto
Otro cambio. Probé Gemini, probé el modo Auto. ¿Por qué? A veces simplemente quieres ver si hay algo mejor. Y a veces lo hay, para ciertas tareas.
Septiembre-Diciembre: Vuelta a Claude
Los modelos nuevos (3.7, 4, 4.5) mejoraron. Volví. No por lealtad, sino porque funcionaban mejor para lo que necesitaba.
Lo que aprendí
1. Los benchmarks no son tu código
Un modelo puede liderar en HumanEval y ser horrible para tu stack específico. O al revés.
Tu proyecto tiene dependencias raras, patrones que solo tú usas, contexto que ningún benchmark captura.
2. Los modelos cambian (y tú también)
El Claude de marzo no es el Claude de diciembre. Literalmente son versiones diferentes con comportamientos diferentes.
Y tus necesidades también cambian. Lo que funcionaba para un proyecto puede no funcionar para el siguiente.
3. “Mi modelo favorito” es una trampa
Cuando te conviertes en fanboy de un modelo:
- Ignoras sus fallos (“será cosa mía”)
- No pruebas alternativas (“¿para qué?”)
- Pierdes tiempo defendiéndolo en Twitter
Mientras tanto, alguien sin lealtad está usando lo que funciona.
4. El modo Auto no es tan malo
Tenía prejuicio contra el selector automático. “Yo sé mejor qué modelo usar.”
Pero hay períodos en mi gráfica donde Auto me funcionó bien. A veces la mejor decisión es no decidir.
Guía práctica
Señales de que debes probar otro modelo:
- El modelo “arregla” cosas sin que entiendas cómo
- Los errores desaparecen mágicamente (spoiler: no desaparecen)
- Llevas tres intentos explicando lo mismo
- El código generado es cada vez más largo y enrevesado
Estos son ejemplos de lo que llamo fallos conceptuales de los LLMs: el modelo no sabe que no sabe.
Cómo probar sin perder tiempo:
- Ten 2-3 modelos configurados y listos
- Cuando algo falle, prueba el mismo prompt en otro
- No migres todo, solo lo que no funciona
- Dale una semana antes de decidir
Lo que NO hacer:
- Cambiar de modelo cada hora
- Asumir que el más nuevo es el mejor
- Asumir que el más caro es el mejor
- Discutir en internet sobre cuál es mejor
Conclusión
Mi gráfica tiene más colores que un arcoíris. Y eso está bien.
No estoy casado con ningún modelo. Uso Claude cuando funciona, GPT cuando funciona mejor, Gemini cuando quiero probar, Auto cuando no quiero pensar.
El mejor modelo es el que resuelve TU problema HOY. Mañana puede ser otro.
No seas fanboy. Sé pragmático.
También te puede interesar
El 95% no ve resultados con IA (y por qué es normal)
La curva J de adopción que nadie te cuenta. Por qué la productividad cae antes de subir cuando adoptas IA.
Usar IA costaba 1000€. Ahora cuesta 1€. ¿Cuál es tu excusa?
El coste de la IA ha caído 1000x en dos años. Si no la usas, no es por dinero. Es por miedo, desconocimiento o pereza.
La IA no te quita el trabajo. Te lo quita alguien que la usa mejor que tú.
Excel lleva 40 años y casi nadie lo domina. La IA va a ser igual. Tu ventaja no es la herramienta, es el tiempo que llevas usándola.